
プログラミング / 言語の歴史
- 2017年12月13日:作成 12年間放置されていた予定項目です(^_^;)
プログラムの誕生
プログラムはコンピュータと同時に誕生した、とは言いきれない部分があります。少なくとも私達が想像するソフトウェアとしてのプログラムは遅れて考案されました。
世界初の電子式計算機であるABC(Atanasoff Berry Computer、1939年開発)やその次のENIAC(Electronic Numerical Integrator And Calculator、1946年開発)は、Wired Logicと呼ばれるハードウェア(真空管)の結線で論理回路を構成する方式でプログラムはハードウェアの一部でした。当然、別の計算をしたいときには配線をやり直さねばならず、次々に異なった計算を行なうことほほぼ不可能でした。
注:1943年に、イギリスで暗号解読用計算機Mark-Iが開発されていますが、これは電子式ではなく機械式(リレー接点方式)計算機です。
ENIACのスタッフはこの欠点を解決すべく、後継機であるEDVAC(Electronic Discrete Variable Automatic Computer)の開発に取りかかります。その中の一人、数学者ジョン・フォン・ノイマン(John von Neumann)が(同僚スタッフのアイディアをパクって無断で取りまとめて個人名で ^_^;)1946年に汎用ハードウェアにプログラムをデータとして与えこれを実行させる方式を発表しました。このとき私達が知るプログラム(ソフトウェア)の概念が生まれています。
このアイディアは1949年にイギリスのEDSAC(Electronic Delay Storage Automatic Calculator)によって実現されます。あれ、EDVAC(アメリカ)は?って、ノイマン君のスタンドプレー(しかも軍事機密漏洩)で同僚達がぶっちぎれ・・・(^_^;)。
この方式は現在ではノイマン型コンピュータ(von Neumann-type computer)と呼ばれており、その特徴は以下の3点に集約されます。
- プログラム内蔵方式 (stored program concept)
- プログラムは記憶装置に保持される
- 逐次制御方式 (sequential system of implementation)
- 記憶装置から実際の処理を行うレジスタ(register)にプログラムがステップごとに逐次取り込まれ実行される
- 2進数処理 (binary number system)
- レジスタは電流のON/OFFを1と0に解釈する
なにそれ?単なるコンピュータぢゃん!って、まったくその通りです。人工知能の実験用などを除けば現在稼動しているコンピュータはすべてノイマン型コンピュータと思って間違いはありません。唯一の変更点は電流のON/OFFを行うとスイッチングに伴うタイムロスが発生し高速化できないため、電圧の高低で1と0を表現するようになったぐらいです。半世紀を経ていまだに通用する、優れた着想であったと言えます。
この方式以外あり得んだろう、その場にいたら俺が提案した!と言う声も聞こえそうですが、仮にいずれ誰かが到達する当たり前の結論であっても、そのパイオニアには名誉が与えられるべきです。
着想に論理的裏付けを与えた事は確かですが、ノイマン氏だけがコンピュータの父と呼ばれて(しまって)います。プログラム内蔵方式を基本設計したコンピュータの真の父、ジョン・エッカート(John Presper Eckert)とジョン・モークリー(John William Mauchly)の両氏を称えよ!
軍事目的開発に見切りをつけた二人はエッカート・モークリ社を設立、1950年に世界初の商用コンピュータUNIVAC I(Universal Automatic Computer I)を開発、UNIVACはコンピュータの代名詞となり(商売には失敗したため直系ではありませんが ^_^;)現在のUnisys社へ発展しています。
プログラミング言語の発達
ノイマン型コンピュータは、人間の指示を何らかの規則でプログラムとして記述し外部から与えなければ動作しません。このプログラムの記述規則を言語と呼びます。
ところが、ノイマン型コンピュータのレジスタは0と1しか判断しません。必然的にプログラムの保持と演算は2進数で行われますが、2進表現のままでは桁数が膨大になり、かつ0と1の並びを人間が理解する事が困難であるため効率の良いプログラム開発は望めません。
しかし何進法で表現しても絶対数は変りませんから、2進数の桁(bit)をまとめて記数法を変えて人間に判りやすくする方法が考えられました。本来なら人間に一番フレンドリーな10進数が良いに決まっています。しかし、bitをまとめる=2の累乗では10進数は作れませんから、普通は16進数が使われています。
おそらく、プログラムの開発効率、人間の負担、実用最低と考えられるレジスタ幅が4bit(ENIACですら4bit)*、慣れ親しんだ10進数、これらが収束した結果が16進数ではないでしょうか。2進を基本とするノイマン型では合理的な、限りなく必然に近い結論だと私は思います。
2020.03.28 追記:*このbit概念はノイマン型でなければ意味を持たず、良く考えれば(考えるまでもなく)ENIACはノイマン型ではありません・・・トイウコトデ削除いたしました m(_ _)m
Wikipedia/ENIACによれば内部10進で動作するとなっていますが、レジスタの構造については私の知識不足で理解できません (^_^;)
2進4桁である0000~1111が16進の1桁(10進の0~15)を表すので、まず4桁を単位としてまとめ16進1桁で表現します。1桁では16通りの命令しか記述できずアルファベットも表せないので、さらに16進の2桁をまとめ16の2乗=256まで表現可能にし、これを最小単位としてコンピュータは処理を行ないます。この最小単位をbyteと呼び、この場合なら1byte=8bitとなります。
また、byteの概念を導入することで、コンピュータは機械的に(って機械ですが(^^ゞ)先頭からbyte単位で逐次取り出して処理すればよくなり、システムの単純化も可能になります。超巨大プロジェクト、しかも国家の威信どころか存亡をかけた軍事目的開発、エンジニアの負担よりこの機械の都合が主要因だったかもしれません。
この根本となるbyte単位処理ですが、CPUの方言、8086系と68000系で異なると言う問題があります。68000系CPUでは11223344と言う値をそのままの順番で11223344とメモリに格納する直観的で解りやすいビックエンディアン方式ですが、8086系ではそれをわざわざ逆順の44332211として格納するリトルエンディアン方式をとっています。そして困った事に、この解りにくいリトルエンディアンの8086系が現在の主流となってしまいました。まぁ、マシン語に関わらなければ害はありませんが・・・Intelは嫌いです (-"-)。
いわゆる数字は0~9の10個しか無いので、16進数では0~9の次はA(10進の10)~F(同15)を用い、7FとかB8のように表記します。この機械が唯一理解し実行できる16進数の命令コードをマシン語(machine language)と言います。
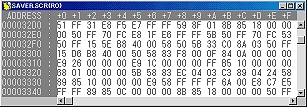
コンパクトでマシンの性能を100%引き出すことが可能ですが、その最大の欠点は(普通の ^_^;)人間に優しくないことです。参考に私が作ったプログラムの中身を示します。確かに2進の00111111 10111000より16進の7F B8の方がマシではありますが、やはり機械のための言葉であり人間がこれを直接理解するのは困難です。
そこで、まずマシン語の16進命令コードを1対1に対応するニーモニック(mnemonic)に置き換えます。ニーモニックはその命令の内容が類推可能なアルファベットの省略形で、8086系CPUであればJamp命令は11101011(2進)=EB(16進)=JMPとなります。人間はニーモニックでプログラムを記述し、アセンブラ(assembler)と呼ばれる専用プログラムでニーモニックをマシン語に変換して実行ファイルを生成する方法が登場します。
これがアセンブリ言語(assembly language)で、無味乾燥な16進数の並びよりは理解しやすくなりましたが、単純にマシン語の数字を単語に置き換えた、マシン語プログラムの記述方法にすぎません。事実上、アセンブリで書く=マシン語で書くであり習得は困難です。
アセンブラは人間語と機械語の単語変換機にすぎませんが、さらに発展させて文法まで置き換える言語変換機=人間と機械の通訳であるコンパイラ(compiler)が登場します。
注:コンパイラの着想は最初からあったが、技術的制約でアセンブラしか作れなかった可能性も有りますが、実現した順番に理論も発展したと決め付けています。これに限らず全般にそうですが(^^ゞ。
人間は、より人間の言葉や発想に近く融通が利くプログラミング言語の規則に従ってソースコード(source code)を記述します。通例、単なるテキストファイルです。ソースコードはコンパイラで、マシン語に変換され実行可能ファイルになります。この実行可能なバイナリファイルのことをオブジェクトコード(object code)とかネイティブコード(native code)と呼びます。
注:逐次変換方式であればインタプリタ(interpreter)がソースコードの変換と実行を同時に行ないます。それを言語の仕組みの範疇で考えると話が一挙に複雑になりますので、インタプリタはプログラムを実行する仕組みと考えて、ここでは無視しました (^^ゞ。
人間が理解し自然に記述できると言う目標は同じですが、それを実現する思想の違いから、様々なプログラミング言語が考案されてきました。そのような人間よりの言語を高水準(高レベル)言語、機械よりで人間に判り難い言語を低水準(低レベル)言語と呼び、区別します。
世界初の高水準言語は、1956年にIBM社が開発したFortran(FORmula TRANslater、フォートラン)です。その後、1960年のCOBOL(COmmon Business Oriented Language、コボル)、1962年のLISP(LISt Processor、リスプ)、1963年のBasic(Beginner's All-purpose Symbolic Instruction Code、ベーシック)、1968年のPascal(Philips' Automatical Sequence Calcurator、パスカル)、トドメは1972年のC言語(C Language、シーゲンゴ)と、次々に開発されます。
これらのプログラミング言語は手続き型言語(procedural language)と関数型言語(functional language)に大別されます。両者は根本的に思想が異なるのですが、特に気にする必要はありません。なぜならば、ほぼすべての言語が手続き型言語に属し、普通に使用されている関数型言語はLispぐらいしかありません(SchemeはLispの方言らしいです)。
手続き型言語では(1)記述された命令は逐次実行される、(2)その結果で変数の内容が変化する、(3)その変数は次の命令に引継がれていく、と言う処理が行なわれます。既にこの思想に汚染(洗脳)されている私たちには、理解に苦しむほど当たり前に感じられます、他にあるのか?と。
あるんです。関数型言語の場合は(1)変数は最初に与えられた値を維持する、(2)関数(命令)の結果は計算式として求まる、(3)その計算式を引数として次の関数を呼び出す、これを延々と繰返して処理を行ないます(理解できない、間違っているかもしれません ^_^;)。手続き型言語と比較して速度は劣るが、数学的な美しさを備え構造が把握しやすく開発効率が高いと言われています。現在でも人工知能研究などに使用されているようです。
Lispも含めこれら言語のフリー開発環境が供給されていますから、興味があれば チャレンジして下さい。なお、各言語の特徴はフリーの開発環境でまとめています。
通訳を介して会話する場合、確かに意味は通じ用は足りたが冗長で回りくどい表現になる事があります。コンパイラも同様で、生成されたオブジェクトコードは、最初からマシン語で開発されたコードと比較すると無駄が多く実行速度が犠牲になります。
高水準言語が普及し一般的ではなくなりましたが、マシン語はけして過去の存在ではありません。今のところ完璧な最適性を実現したコンパイラが存在しないので、高速でハードウェアを制御する必要のあるデバイスドライバなどはマシン語(アセンブリ言語)で開発されています。今もどこかで円形脱毛に苦しみながらマシン語を書いているエンジニアがいるはずです(^_^;)。
注:たまに見かける、8bitを1byteとしてまとめ、その上位下位の4bitをそれぞれ16進数に置き換えて・・・とされている解説がありますが、それでは因果関係が逆転してしまいます。CPUがする事、結果は同じですが、byte概念は下からbit処理を積み上げた場合の処理最小単位であるはずです。